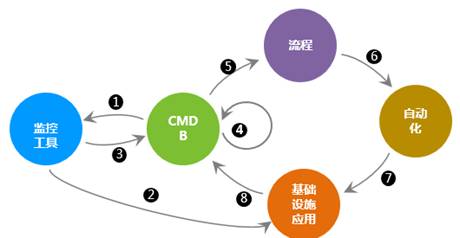
云时代下的CMDB建设难题
CMDB发展历史
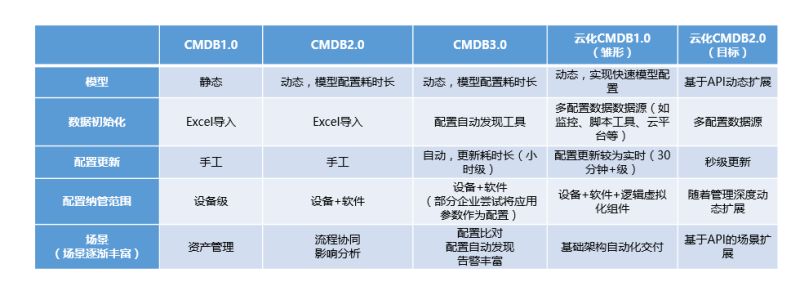
CMDB建设常见问题
- 缺乏合理化、整体化的规划
需求不清晰,定义了不合理的配置广度和深度。
在大而全? 还是小而深? 方面犹豫不决: 这种决策机制在项目初期往往耗费了大量时间,但随着新技术的不断涌现,这种方式已经无法适应越来越敏捷的IT环境,我们发现一种相对静态的CMDB模型已经不能满足纳管新IT组件的要求。
如何解决?
用一种更为灵活的CMDB模型扩展机制。
采用了不正确的管控策略: 按照经典ITIL的管控和项目实施机制,配置管理规划,尤其是CMDB模型的规划往往由项目组承担,一旦规划完成后整个模型也就变得很难再进行扩展,应该说这里采用的是一种集中管控的策略。
但在实际IT运维工作中,我们发现对于CMDB使用最多的是各个二线团队,不同团队之间对于CMDB 深度和广度的要求,以及管控方式都有较大差别。
如何解决?
基于集中分布式的理念建立CMDB管控体系
- 配置管理人员职责定义不清晰
配置经理、配置管理员、配置Owner之间职责不清晰:
按照ITIL或ISO20000中对于这三类角色的定义往往过于宽泛,没有进一步考虑实际运维人员的运维场景,以及使用的运维工具,导致职责定义和实际做事方式脱节。
如何解决?
结合运维场景、运维工具、流程角色职责,对于各角色的职责进行重定义。
角色职责和岗位的对应不明晰:
在没有ITIL以前,在企业IT部门或数据中心往往找到不到一个现成岗位对于IT配置信息进行集中管理,而是每个人各管一摊。
实施ITIL后,究竟由哪个部门的哪个岗位承担配置经理这一职责往往是最让人伤脑筋的,最后往往是赶鸭子上架。这种角色定义方式最终导致体系无法运转。
如何解决?
基于集中分布式的理念设定角色和岗位的对应关系
- 配置管理成了IT运维的负担
这其实是CMDB在企业落地所面临的最大挑战,无法充分调动运维人员的积极性,主要体现在:
初始数据收集工作量大: 存量的配置数据往往基数很大,一般配置的量级在5000以上,考虑到云化环境的海量运维场景,这个基数还会更大。
随着分布式应用架构以及微服务架构的兴起,未来一套新应用系统上线引入新的配置项数量也无法简单通过手工输入的方式来完成。
如何解决?
借助自动化手段进行数据采集
单一的自动化配置发现工具只是一种幻想: 如前所说,约从2007年开始,业内引入了自动发现工具用以解决配置数据的初始化问题,但由于这类工具往往由某个厂商提供,导致了配置发现的局限性,企业往往也要付出较大成本。
如何解决?
建立适配多类自动化工具的CMDB架构,将企业现有的脚本、监控工具、自动化工具、云平台都转化为配置数据的提供方。
投产后由于变更频繁,数据无法保证及时准确: 以往企业一般采用变更操作驱动配置修改(人工修改、或自动化发现修改)的方式以确保配置数据的准确性,这种方式往往出现了配置信息的不一致。
如何解决?
建立基于配置基线驱动的IT环境变更(操作)架构,即建立通过配置修改事件触发变更操作的事件响应模型。 对于未来软件定义环境,这种架构是一种必然选择。
如何让人人“乐于”参与: 这里的参与主要体现在二个方面: 1)需要使用与自己相关的配置数据时,CMDB可以立即提供; 2)遇到CMDB无法提供的数据时,IT部门可自行在一定标准和约束下扩展满足本部门运维CMDB模型,支撑部门级的运维场景。
如何解决?
建立小、快、灵的CMDB架构,支撑快速扩展、快速纳管、快速交付数据。
- 配置数据的价值无法呈现
缺乏清晰的场景定义,包括流程价值、监控价值、BSM价值、云价值等: 单一流程驱动CMDB的场景,无法让CMDB中的数据流动起来,随着时间的推移CMDB中的数据就逐渐腐败—不及时也不准确。
同时,CMDB在技术上作为一个“数据库”,要让其中的数据能够流动起来,必须明确与之匹配的运维场景。
场景是用来描述与CMDB中某些配置项交互的一组活动,满足IT部门某一方面的运维管理目标,这一目标可以被度量、跟踪、改进、可视化,与此同时,CMDB的价值也随之呈现。
如何解决?
建立基于场景驱动的CMDB解决方案集合;
缺乏有效、明确的配置数据集成策略: 如前所述,CMDB是一个逻辑上的数据库,其中的数据需要和企业现有IT环境中的多类数据源进行整合,一套行之有效的数据集成策略和ETL(数据抽取、转换、转载)工具也必不可少。
如何解决?
建立数据集成策略,引入ETL。
通过以上分析,我们回顾了CMDB的历史发展过程,以及建设过程中遇到的挑战。接下来我们看看云化环境下CMDB又将面临什么新问题。
云时代的特点以及带来的挑战

云化CMDB应具备的典型特征和范式
在云化时代,CMDB需要从原有的单一工具转变为一种企业IT服务能力,即CMDB As A Service(以下为了便于叙述,使用云化CMDB代替)。
云化CMDB:是指 CMDB消费者可以通过网络随时随地获取、维护、管理CMDB。
如IaaS中服务要素是指IT基础架构,在云化中的服务要素包括三个层面:
配置模型:用以描述CMDB的深度和广度,在技术上体现为一组配置标签(如服务器、网络、应用等,或生产环境、测试环境等)、与配置标签相关联的配置对象、以及用于描述配置对象的属性集合。
配置模型是用以描述配置项的元数据,其描述了某一配置项应该具备的属性,以及该配置项与其他配置项之间的逻辑关系,以及与配置项相关的一组操作。
配置项:用以描述某一配置对象的具体实例。如对于Server这个配置对象,其具体的IT环境中可能表现为IBM Server01,IBM Server02,IBM Server03等服务器实例。
配置项的关联操作:这个层面是对ITIL的补充。操作用来描述某个配置项在实际特定的IT环境中允许进行的一组行为集合。
举例来说,对于IBM Server01配置项来说,可能有的操作包括启动、停止;对于比较复杂的应用系统APP 01来说,可能有的操作就包括启动、停止、重启、配置等。
如果说配置项属性是对配置项的静态描述,那么配置项操作就是对配置项的动态描述,其描述了消费者可以对当前配置项施加的动作。
上述服务要素并不能单独存在,这就像数据库管理系统中的数据一样,在没有被业务系统使用前,都只是一堆0和1组成的数据,必须放到某个特定的上下文中才具备其特定的含义。
这里说的业务系统其实说的就是场景。配置场景描述CMDB与某个具体运维活动或业务活动之间的关系,在一个场景中可能同时触发一组关联操作。
在没有JDBC或ODBC标准接口前,存放在数据库管理系统中的数据只能通过特定的数据库管理平台才能进行增、删、查、改操作,这种方式严重制约了数据库中的数据对外提供服务和消费,给业务系统的开发带来了极大的不便利性。
同理,在CMDB As A Service理念中,我们也需要通过把服务要素API化,将CMDB的服务能力真正暴露出去,以便于场景进行调用。
CMDB API与服务要素一一对应,包括三个层次:
配置模型的增、删、查、改(类似于DML); 配置数据的增、删、查、改;配置项关系建立、移除(类似于DDL); 配置操作的增、删、查、改;并建立配置操作与特定的IT运维自动化工具的关联(包括脚本、专业自动化运维工具、云平台、监控平台等等); 注:其实Puppet、Chef在架构上已经采取了类似的理念,这里我们希望再往上抽象一个层次
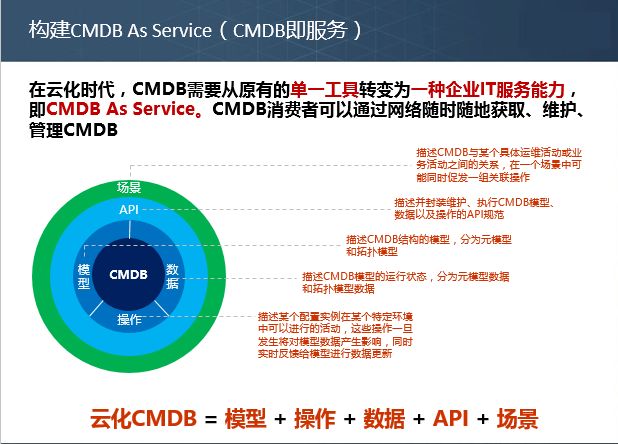
通过上述要素的组合,我给出云化CMDB的定义:
云化CMDB=模型 + 操作 + 数据 + API + 场景
云化CMDB的基本架构
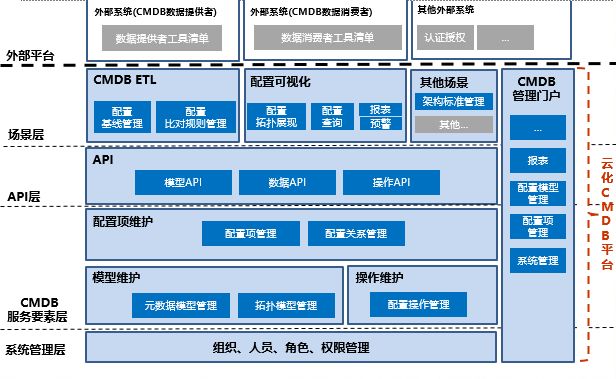
整个云化CMDB平台自下而上分为四个层次,分别是:
系统管理层:该层为系统的使用提供了最基本的支持,包括组织、人员、角色、权限的管理。支持定义各类角色和权限的管理,有完整的角色管理和权限管理功能,权限配置支持组嵌套。并通过与外部IT管理云平台集成实现用户的统一认证功能
CMDB服务要素层:按照云化CMDB的理念,服务要素包括模型、数据和操作,与之对应的分别是模型维护、配置项维护和操作维护功能。
API层:通过封装底层CMDB服务要素层的功能要素,对外提供模型管理API、配置项管理API和操作API
场景层:场景层采用了一种可扩展的方式进行设计,CMDB ETL和配置可视化是CMDB的两个基本场景:
场景一:其中CMDB ETL主要实现对于多外部配置数据源的数据抽取、转化和处理,并将处理的结果通过API层的配置项API进行数据录入,并记录配置数据的变化,建立配置基线,并围绕基线形成基线比对等功能;
场景二:配置可视化主要针对配置数据提供一种展示(图形、声音、文字等)手段,包括配置拓扑展现(以图形化方式展现配置项间的关联关系)、配置项多维度查询、配置报表以及预警功能。
除了基本场景外,开发人员可以通过API层的功能,并结合基本场景实现自定义场景,比如在本次项目中实现架构标准配置比对功能就是一种基于配置比对功能基础上的新场景应用。
除了以上层次,平台提供了CMDB管理门户的GUI界面,便于系统管理员和配置管理相关用户对于模型、配置项进行维护、查询。