
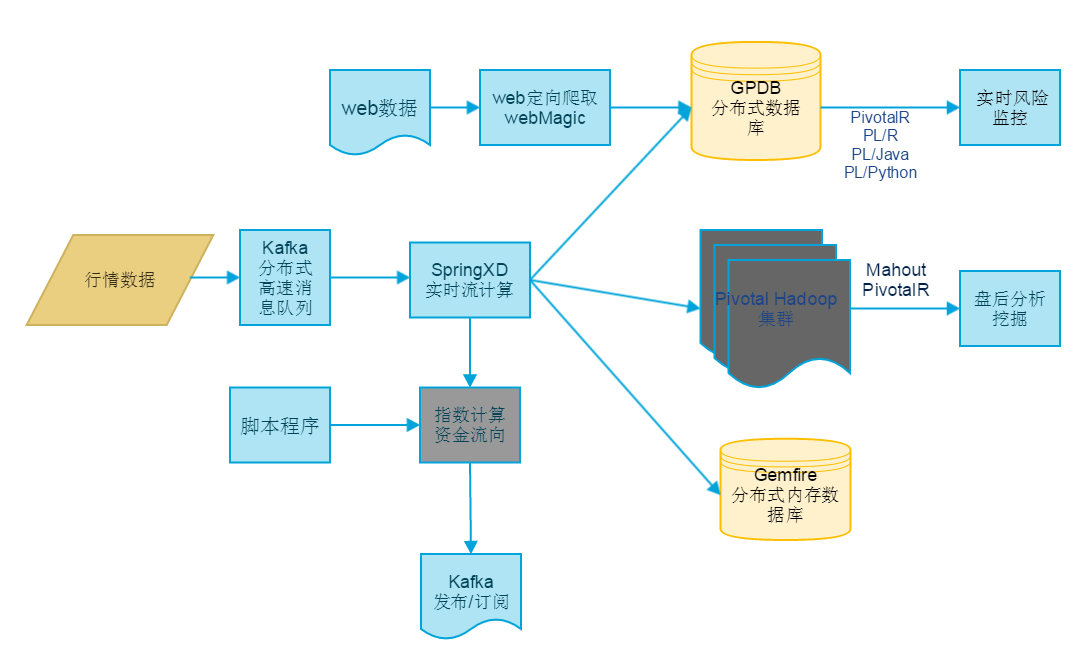
###SpringXD流处理举例
####1. 金融高频数据 首先在GPDB中创建一个表,用来接受金融高频数据,这里用行情数据price举例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
create table price(
id bigint,
bondid_type integer,
bondid integer,
bondcode varchar,
price_status char,
product_status char,
trade_date varchar,
trade_time varchar,
trade_time2 integer,
trade_time_int integer,
preclose float,
open float,
high float,
low float,
current float,
volume integer,
turnover float,
trade_num float,
total_BidVol float,
total_AskVol float,
Weighted_Avg_BidPrice float,
Weighted_Avg_AskPrice float,
IOPV float,
Yield_To_Maturity float,
High_Limited float,
Low_Limited float,
pe1 float,
pe2 float,
delta float,
Ask_Price1 float,
ask_volume1 float,
ask_order1 integer,
Ask_Price2 float,
ask_volume2 float,
ask_order2 integer,
Ask_Price3 float,
ask_volume3 float,
ask_order3 integer,
Ask_Price4 float,
ask_volume4 float,
ask_order4 integer,
Ask_Price5 float,
ask_volume5 float,
ask_order5 integer,
Ask_Price6 float,
ask_volume6 float,
ask_order6 integer,
Ask_Price7 float,
ask_volume7 float,
ask_order7 integer,
Ask_Price8 float,
ask_volume8 float,
ask_order8 integer,
Ask_Price9 float,
ask_volume9 float,
ask_order9 integer,
Ask_Price10 float,
ask_volume10 float,
ask_order10 integer,
bid_Price1 float,
bid_volume1 float,
bid_order1 integer,
bid_Price2 float,
bid_volume2 float,
bid_order2 integer,
bid_Price3 float,
bid_volume3 float,
bid_order3 integer,
bid_Price4 float,
bid_volume4 float,
bid_order4 integer,
bid_Price5 float,
bid_volume5 float,
bid_order5 integer,
bid_Price6 float,
bid_volume6 float,
bid_order6 integer,
bid_Price7 float,
bid_volume7 float,
bid_order7 integer,
bid_Price8 float,
bid_volume8 float,
bid_order8 integer,
bid_Price9 float,
bid_volume9 float,
bid_order9 integer,
bid_Price10 float,
bid_volume10 float,
bid_order10 integer,
Pre_Open_interest integer,
Pre_Settle_Price integer,
open_interest integer,
Settle_Price integer,
Pre_Delta integer,
Curr_Delta integer,
Prefix varchar
)
WITH (appendonly=true,orientation=column,compresstype=QUICKLZ,COMPRESSLEVEL=1)
distributed by (trade_date) ;
####2. 在springxd集群中创建一个stream流kafka2gp 这个stream的作用就是从kafka中取对应的topic数据,经过springxd处理,流向gpdb
1
stream create --name kafka2gp --definition "kafka --zkconnect=10.2.29.4:2181 --topic=price --autoOffsetReset=smallest --outputType=text/plain | jdbc --inputType=application/json --columns=id,bondid_type,bondid,bondcode,price_status,product_status,trade_date,trade_time,trade_time2,trade_time_int,preclose,open,high,low,current,volume,turnover,trade_num,total_BidVol,total_AskVol,Weighted_Avg_BidPrice,Weighted_Avg_AskPrice,IOPV,Yield_To_Maturity,High_Limited,Low_Limited,pe1,pe2,delta,Ask_Price1,ask_volume1,ask_order1,Ask_Price2,ask_volume2,ask_order2,Ask_Price3,ask_volume3,ask_order3,Ask_Price4,ask_volume4,ask_order4,Ask_Price5,ask_volume5,ask_order5,Ask_Price6,ask_volume6,ask_order6,Ask_Price7,ask_volume7,ask_order7,Ask_Price8,ask_volume8,ask_order8,Ask_Price9,ask_volume9,ask_order9,Ask_Price10,ask_volume10,ask_order10,bid_Price1,bid_volume1,bid_order1,bid_Price2,bid_volume2,bid_order2,bid_Price3,bid_volume3,bid_order3,bid_Price4,bid_volume4,bid_order4,bid_Price5,bid_volume5,bid_order5,bid_Price6,bid_volume6,bid_order6,bid_Price7,bid_volume7,bid_order7,bid_Price8,bid_volume8,bid_order8,bid_Price9,bid_volume9,bid_order9,bid_Price10,bid_volume10,bid_order10,Pre_Open_Interest,Pre_Settle_Price,Open_Interest,Settle_Price,Pre_Delta,Curr_Delta,Prefix --driverClassName=org.postgresql.Driver --tableName=price --url=jdbc:postgresql://10.2.28.234:5432/fitl --username=gpadmin --password=xxx" --deploy
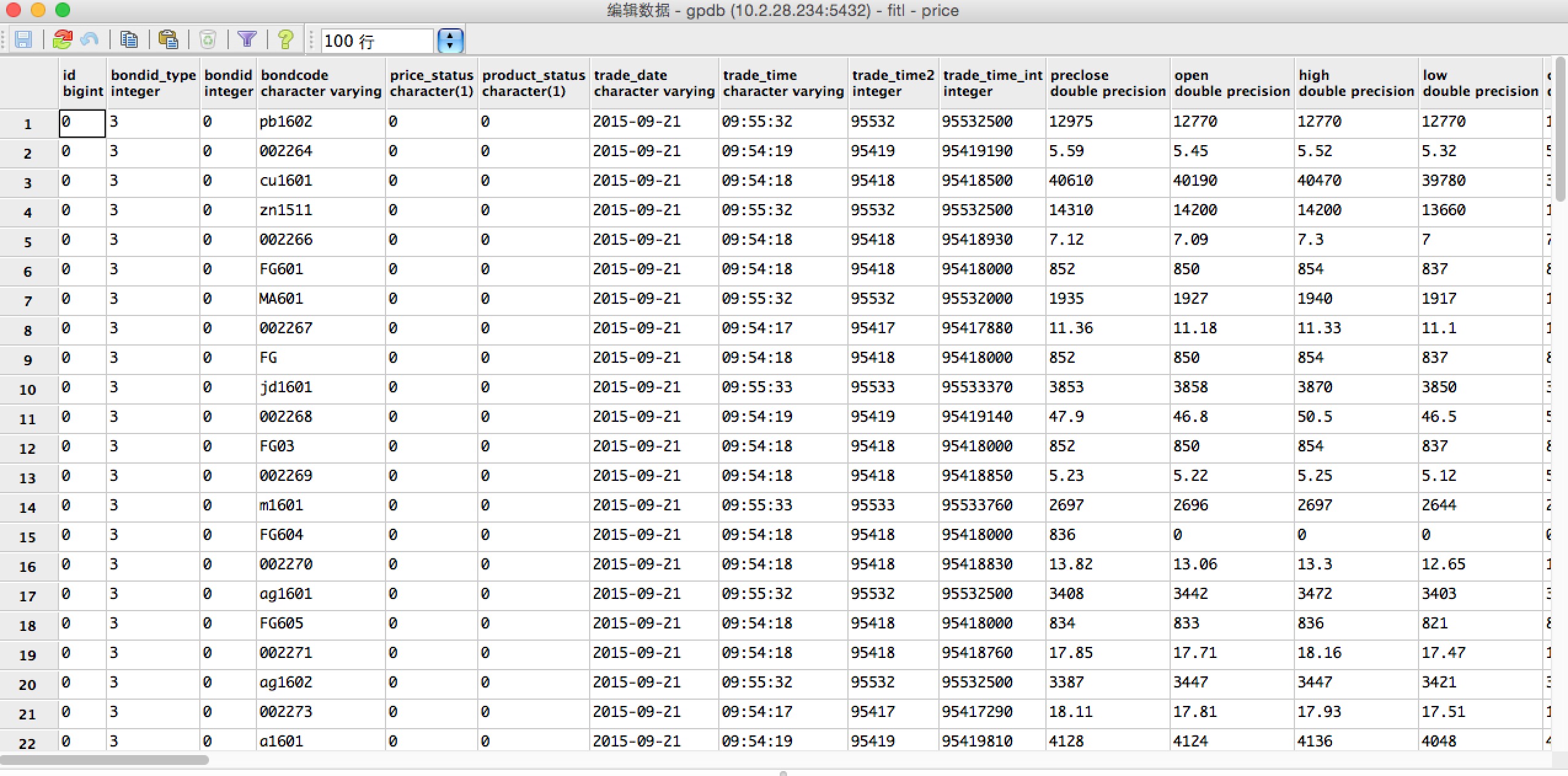
####3. 验证数据是否进入到gpdb的price表 通过pgadmin工具,查看数据表price
####4. 注意
springxd安装后,没有gpdb的jar包,需要将postgresql-9.4-1201-jdbc41.jar包放到1
/opt/pivotal/spring-xd/xd/lib
1
/opt/pivotal/spring-xd/xd/modules/job
####5. 其他流
kafka到文件
1
stream create --name kakfa2fs --definition "kafka --zkconnect=10.2.29.4:2181 --topic=price --outputType=text/plain | file --inputType=text/plain --dir=/opt/test --name=price" --deploy
kafka tap分流到hdfs
1
stream create --name kakfa2fs --definition "tap:stream:kafka2fs > hdfs --directory=/xd/fitl/ --fileName=price" --deploy
http接收数据到hdfs
1
2
stream create --name http2hdfs --definition "http --port=9000 | hdfs --fsUri=hdfs://phd3-m1.xxb.cn:8020 --directory=/xd/fitl --fileName=httphdfs"
http post --target http://localhost:9000 --data "huangjie 3"
####6. 使用job将csv文件导入mysql数据库
将csv文件导入mysql数据库,可以直接使用filejdbc这个job来完成
首先将mysql-connector-java-5.1.34.jar的包放到1
/opt/pivotal/spring-xd/xd/modules/job/filejdbc/lib
1
2
3
4
5
xd:>job create csvmysql --definition "filejdbc --driverClassName=com.mysql.jdbc.Driver --url=jdbc:mysql://gfxd1.xxb.cn:3306/springxd --username=springxd --password=springxd --resources=file:///opt/people.csv --names=forename,surname,address --tableName=people" --deploy
Successfully created and deployed job 'csvmysql'
--调用job
xd:>job launch csvmysql
Successfully submitted launch request for job 'csvmysql'
1
2
3
[root@springxd1 opt]# more people.csv
jian,gong,beijing
chun,lu,guangzhou
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
[root@springxd1 opt]# mysql -uspringxd -h gfxd1.xxb.cn -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 761
Server version: 5.1.73 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use springxd
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from people;
+----------+---------+-----------+
| forename | surname | address |
+----------+---------+-----------+
| jie | huang | shanghai |
| jian | gong | beijing |
| chun | lu | guangzhou |
+----------+---------+-----------+
3 rows in set (0.00 sec)
####7. 使用filejdbc将csv文件导入GPDB
首先将postgresql-8.1-407.jdbc3.jar的包放到1
/opt/pivotal/spring-xd/xd/modules/job/filejdbc/lib
1
job create hjgpdb --definition "filejdbc --driverClassName=org.postgresql.Driver --url=jdbc:postgresql://10.2.28.234:5432/fitl --username=gpadmin --password=gpadmin --resources=file:///opt/people.csv --names=forename,surname,address --tableName=people" --deploy
1
2
3
4
5
6
7
8
9
10
11
12
13
14
fitl=# create table people (forename varchar(20), surname varchar(20), address varchar(20));
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'forename' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE
Time: 26.762 ms
fitl=# select * from people;
forename | surname | address
----------+---------+---------
(0 rows)
Time: 7.581 ms
xd:>job create hjgpdb --definition "filejdbc --driverClassName=org.postgresql.Driver --url=jdbc:postgresql://10.2.28.234:5432/fitl --username=gpadmin --password=xxxx --resources=file:///opt/people.csv --names=forename,surname,address --tableName=people" --deploy
Successfully created and deployed job 'hjgpdb'