Python爬取链家网成交数据
最近要买房
- 上海房价涨的太凶了,有木有?
- 爬爬链家网的数据来看看上海房价高的有多离谱?
- 上海辣么大,买哪里好呢?
环境准备
- 环境工具准备好,就可以开工了
- 这里用到python、mysql、tableau几个工具
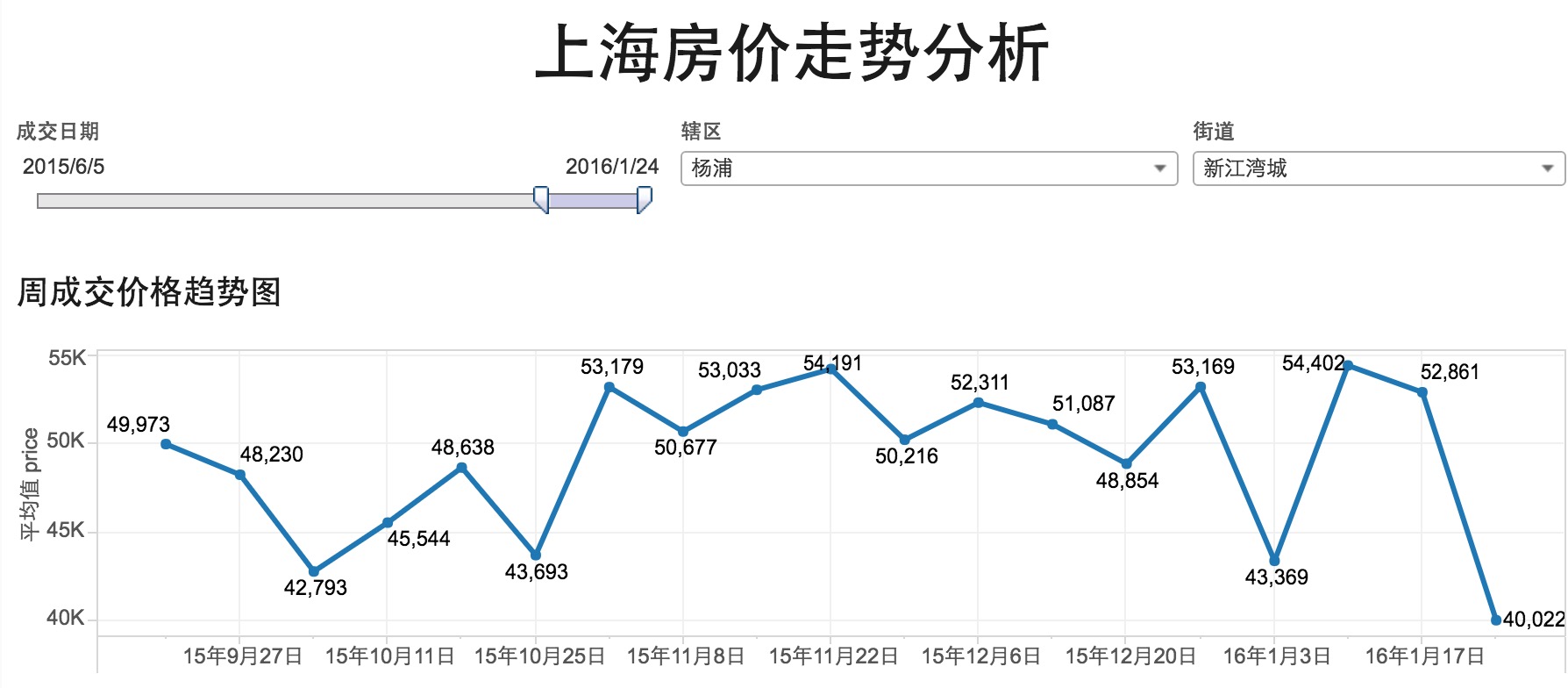
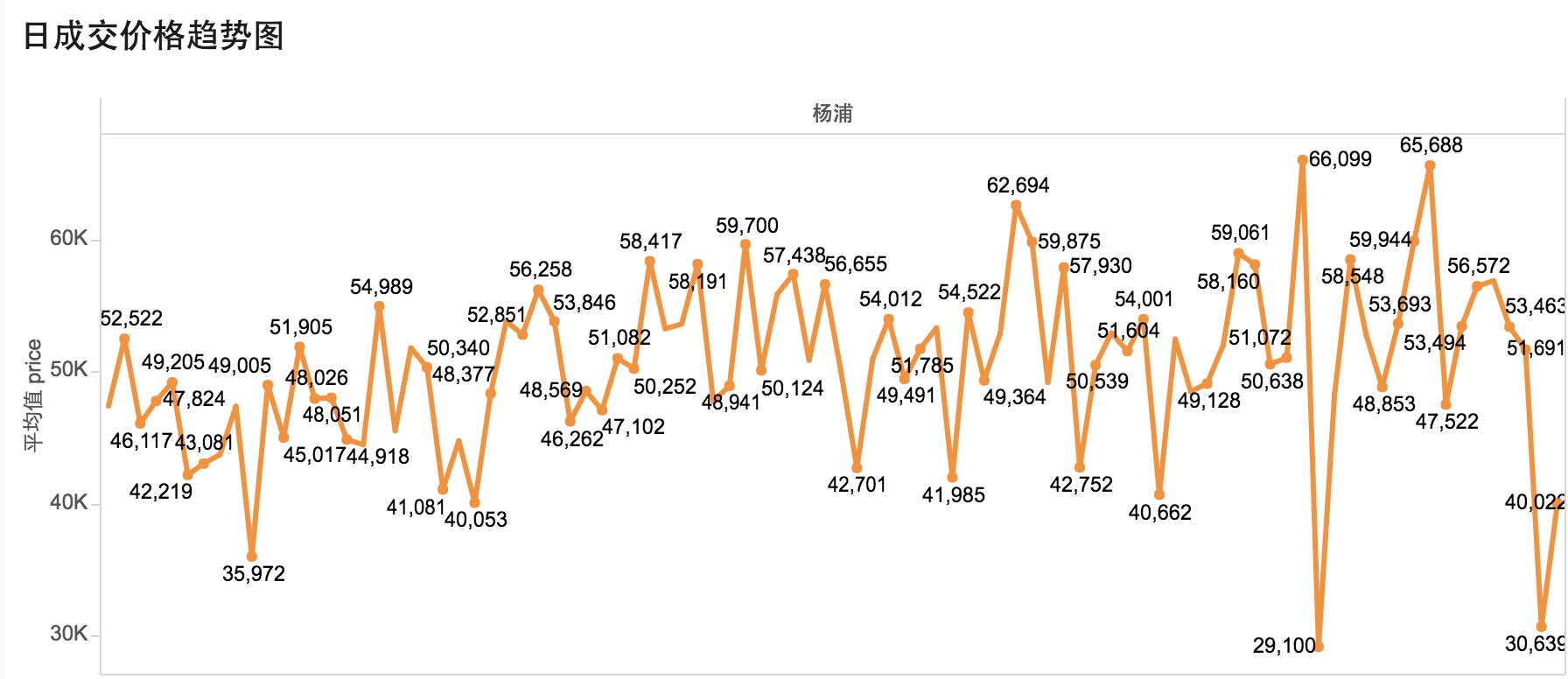
- 主要思路就是链家网上的成交记录数据通过python程序爬下来,存储到mysql数据库中,然后通过tableau数据可视化工具进行简单的分析和展示
爬取核心函数
- 根据上海各区县获取数据,读取链家页面信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def getPage(self,region,pageIndex):
try:
url = 'http://sh.lianjia.com/chengjiao/'+ region + '/d'+ str(pageIndex)
cj = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
request = urllib2.Request(url,headers = self.headers)
respone = opener.open(request)
content = respone.read()
infoencode = chardet.detect(content).get('encoding','utf-8')
typeEncode = sys.getfilesystemencoding()
pageCode = content.decode(infoencode,'ignore')#.encode(typeEncode)
print("page:"+str(pageIndex)+"_connect success..")
print(url)
return pageCode
except urllib2.HTTPError,e:
if hasattr(e,"reason"):
print url
print u'连接数据出错,错误原因:',e.reason
f_error = open('/opt/lianjia/house_trade_error.csv','ab')
w_error = csv.writer(f_error)
w_error.writerow([pageIndex,time.strftime('%Y-%m-%d',time.localtime(time.time()))])
return None
- 从页面中提取所需的字段信息,如成交单号、成交价格、房屋名称、所在区域等等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def getPageItems(self,region,pageIndex):
pageCode = self.getPage(region,pageIndex)
if not pageCode:
print (u"页面加载失败....")
return None
sign ="链家网签约"
sign = sign.decode('utf8')
total = "签约总价"
total =total.decode('utf8')
pattern = re.compile('<div class="info-panel">.*?name="selectDetail.*?key="(.*?)" href="/chengjiao.*?target="_blank">(.*?)</a>.*?'+
'<div class="con">.*?<a href="/chengjiao.*?>(.*?)</a>.*?'+
'<a href="/chengjiao.*?>(.*?)</a>.*?'+
'<div class="introduce">(.*?)</div>.*?'+
'<div class="dealType">.*?<div class="div-cun">(.*?)</div>.*?<p>'+sign+'</p>.*?'+
'<div class="div-cun">(.*?)<span>.*?'+
'<div class="div-cun">(.*?)<span>.*?<p>'+total+'</p>',re.S)
items = re.findall(pattern,pageCode)
#用来存储每页的信息
pageInfor = []
#遍历正则表达式匹配的信息''.join(x)
for item in items:
pageInfor.append([self.rdate,item[0].strip(),item[1].strip(),item[2].strip(),item[3].strip(),item[4].strip(),item[5].strip()\
,item[6].strip(),item[7].strip() ])
return pageInfor
- 获取最大页数
1
2
3
4
5
6
7
8
9
10
11
12
13
def getMaxPage(self,region):
pageCode = self.getPage(region,1)
if not pageCode:
print (u"页面加载失败....")
return None
pattern = re.compile('house-lst-page-box">.*?class="on">.*?<a href="/chengjiao/'+region+'/d7" >7</a>.*?<a href="/chengjiao.*?>(.*?)</a>',re.S)
total_page = re.findall(pattern,pageCode)
try:
return total_page[0]
except Exception,e:
print(e)
return 1
- 写数据到mysql数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def writeDataTotmpTable(self,region,pageIndex):
conn = MySQLdb.connect(self.host,self.user,self.passwd,self.db,charset="utf8")
pageInfor = self.getPageItems(region,pageIndex)
if conn:
if pageInfor:
try:
cursor = conn.cursor()
insert_sql = "insert into tmp_t_house_trade_infor(rdate,house_key,house_name,region_name,\
district_name,house_introduce,trade_date,price,total_amount)\
values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
for i in range(0,len(pageInfor)):
#print(pageInfor[i])
cursor.execute(insert_sql,pageInfor[i])
except Exception,e:
print e
conn.commit()
cursor.close()
conn.close()
else:
print(pageIndex+ ":no data return....")
else:
print("connect database failed....")
- 调度执行
1
2
3
4
5
6
7
8
9
10
11
def start(self):
self.deleteTmpTable()
region_code_list = self.getRegionCode()
for i in range(0,len(region_code_list)):
max_page = self.getMaxPage(region_code_list[i][0])
for j in range(1,int(max_page)+1):
self.writeDataTotmpTable(region_code_list[i][0],j)
time.sleep(5)
self.cal_mysql_produce()
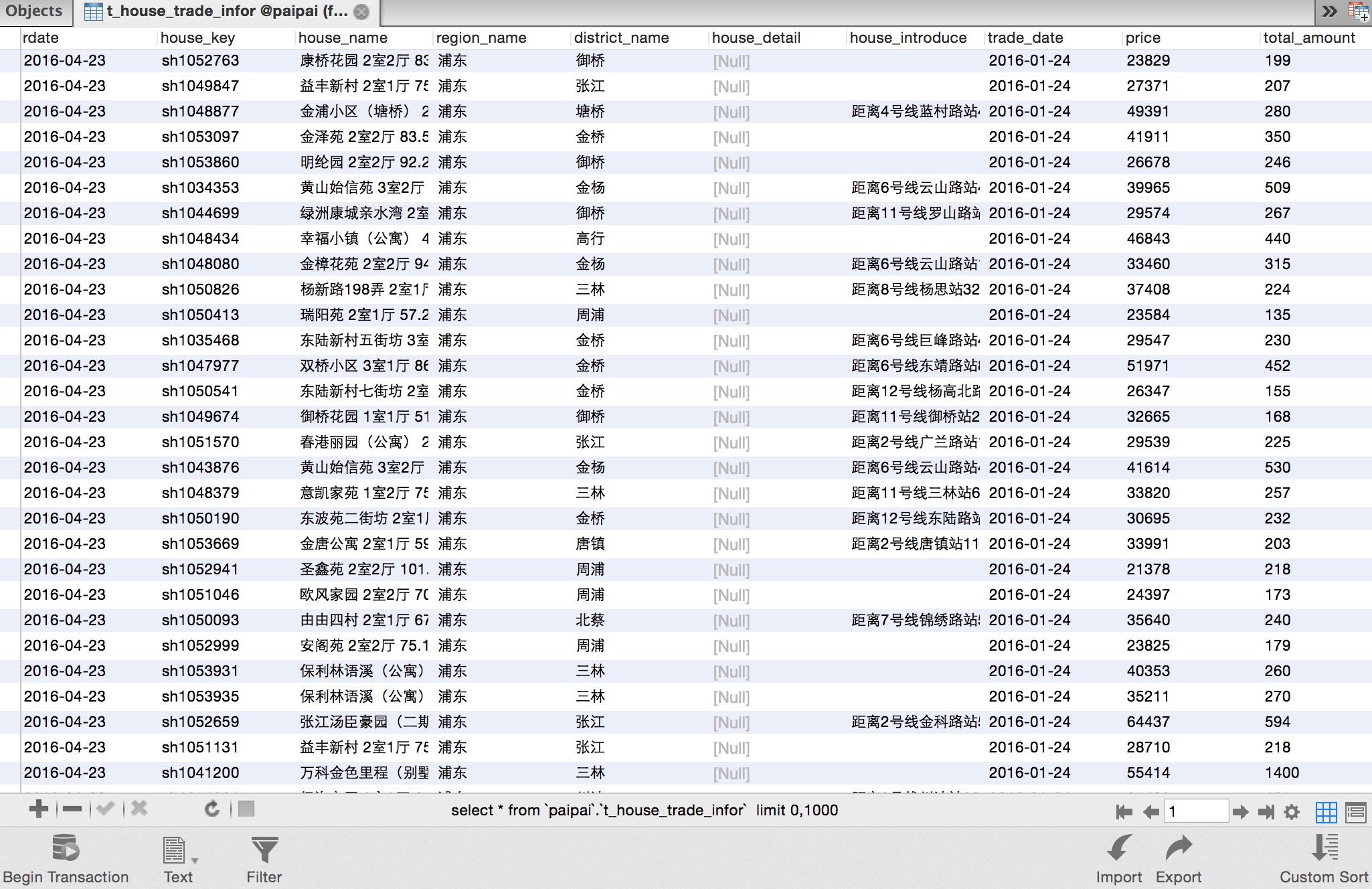
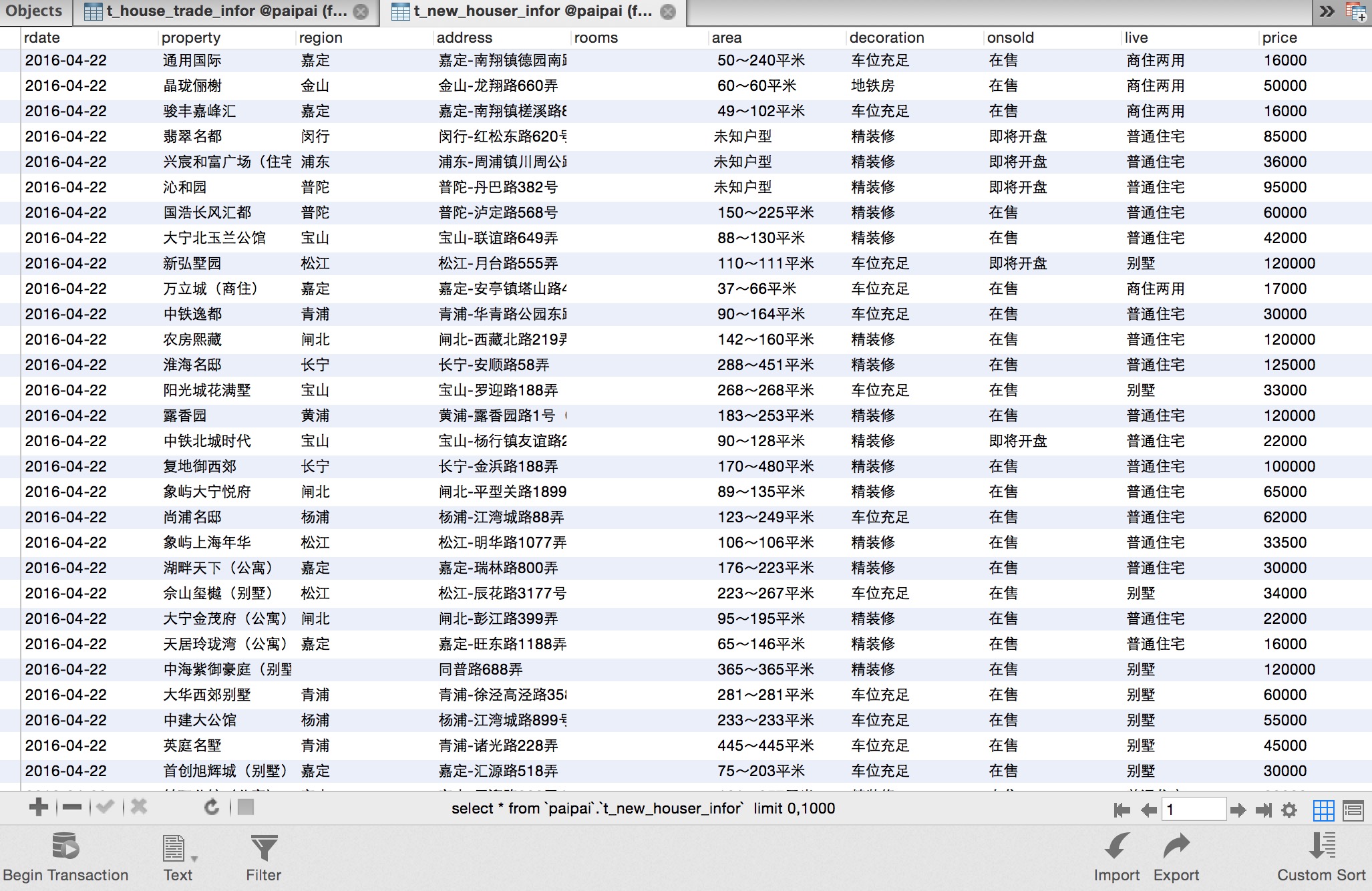
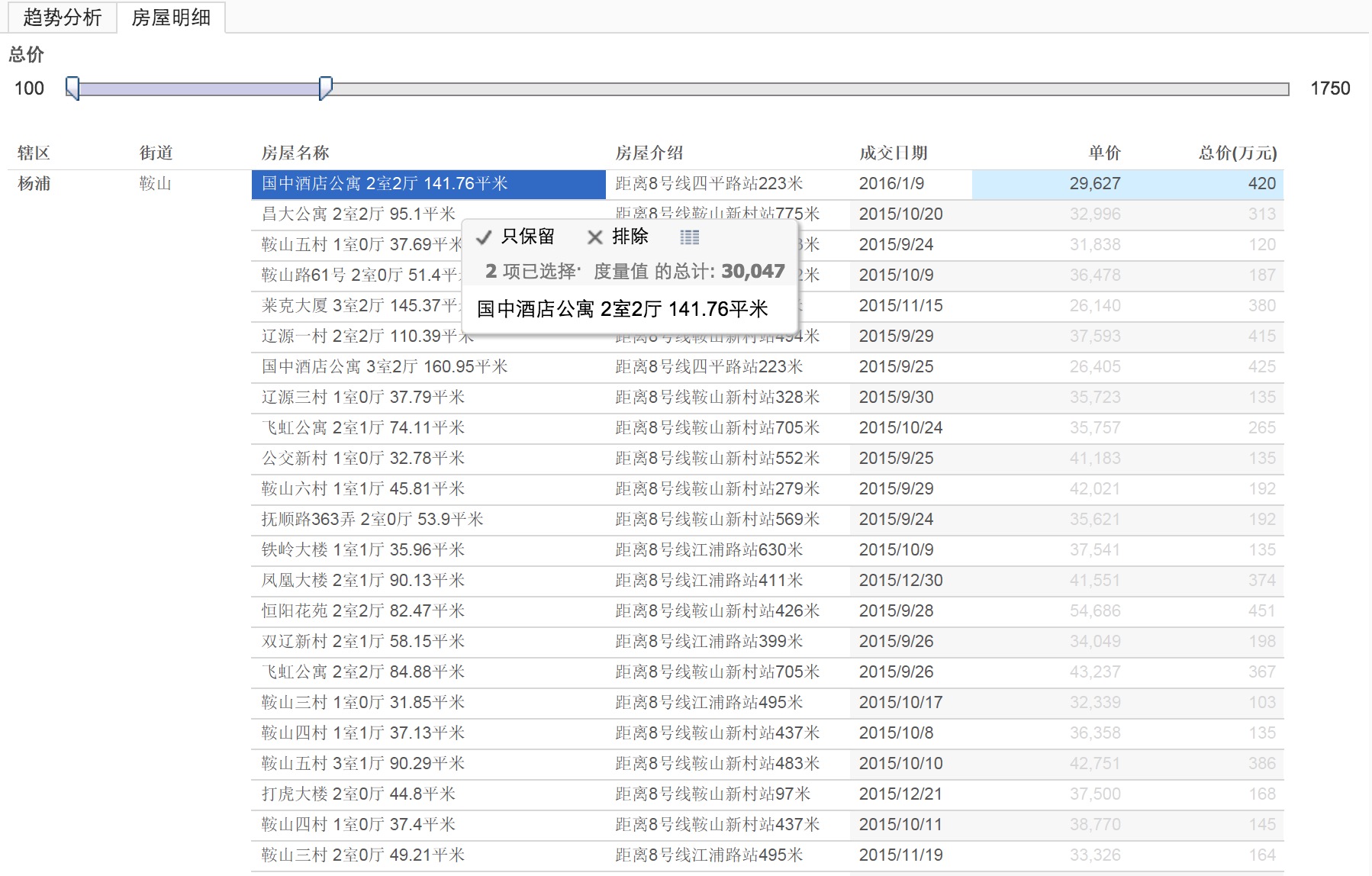
爬取的链家网成交数据及房源数据
- 链家成交中只有最近一年的成交数据
- 只爬取了上海的数据