###Kafka集群的安装和部署
####1. 安装部署zookeeper 因为已经在上一篇文章中部署了Pivtoal HD,所以zookeeper已经部署过了,这里可以直接使用;如果没有现成的zookeeper,也可以使用kafka自带的zookeeper。
####2. 下载kafka
从官方网站下载kafka二进制安装包,解压缩kafka_2.9.1-0.8.2.1.tgz 并修改名称为kafka,存放于1
/opt/kafka
####3. 配置kafka的环境变量KAFKA_HOME、PATH
####4. 修改1
conf/server.properties
1
2
3
4
zookeeper.connect=phd3-m1.xxb.cn:2181,phd3-m1.xxb.cn:2181,phd3-m1.xxb.cn:2181
broker.id=1(其他两个机器是2,3)
host.name=kafka1
log.dirs=/opt/kafka/kafka-logs(文件夹权限为755)
####5. 然后复制kafka文件夹到集群内的其他机器上 注意修改host.name
####6. 启动kafka
1
nohup /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties &
####7. 创建topic
1
2
3
4
5
/opt/kafka/bin/kafka-topics.sh --create --zookeeper phd3-m1:2181 --replication-factor 1 --partitions 1 --topic price
/opt/kafka/bin/kafka-topics.sh --create --zookeeper phd3-m1:2181 --replication-factor 1 --partitions 1 --topic order
/opt/kafka/bin/kafka-topics.sh --create --zookeeper phd3-m1:2181 --replication-factor 1 --partitions 1 --topic orderqueue
/opt/kafka/bin/kafka-topics.sh --create --zookeeper phd3-m1:2181 --replication-factor 1 --partitions 1 --topic transaction
/opt/kafka/bin/kafka-topics.sh --create --zookeeper phd3-m1:2181 --replication-factor 1 --partitions 1 --topic product
####8. 监控kafka 这里使用的yahoo开源的kafka监控工具,先准备sbt环境(sbt是scala的打包构建工具)
1
2
curl https://bintray.com/sbt/rpm/rpm | sudo tee /etc/yum.repos.d/bintray-sbt-rpm.repo
yum install sbt
然后将源码clone下来
1
git clone https://github.com/yahoo/kafka-manager.git
编辑1
conf/application.conf
1
kafka-manager.zkhosts="phd3-m1:2181"
使用sbt编译安装,编译后生成部署包,解压缩后,是一个play的应用,启动即可
1
2
3
4
5
6
cd /root/kafka-manager
sbt clean dist
cp /root/kafka-manager/target/universal/kafka-manager-1.2.5.zip /opt/
unzip kafka-manager-1.2.5.zip
cd /opt/kafka-manager-1.2.5/bin
./kafka-manager &
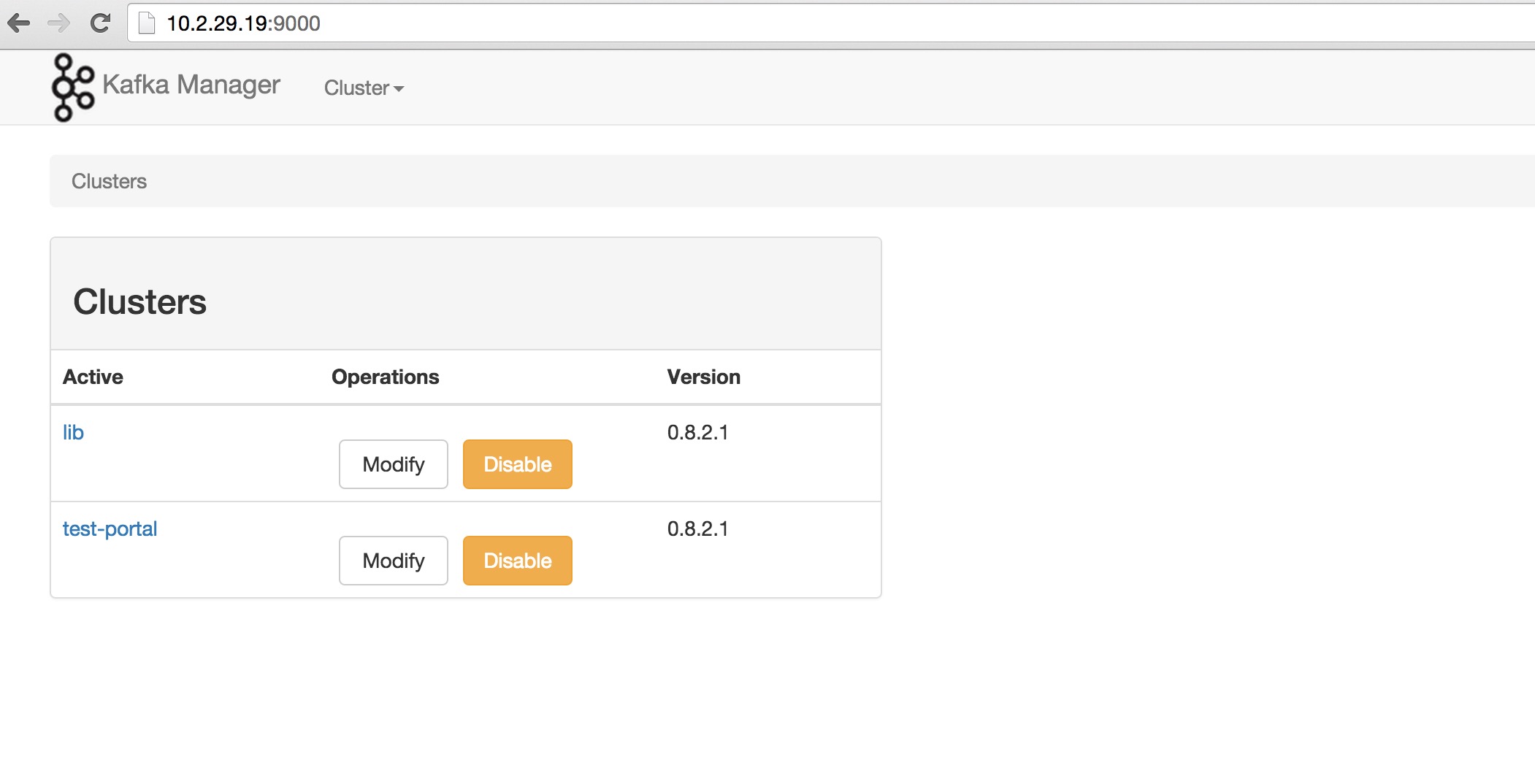
然后通过9000端口访问:
####9. 设置JMX监控kafka性能指标数据
修改1
/opt/kafka/bin/kafka-server-start.sh
1
2
3
4
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export JMX_PORT="9999"
fi
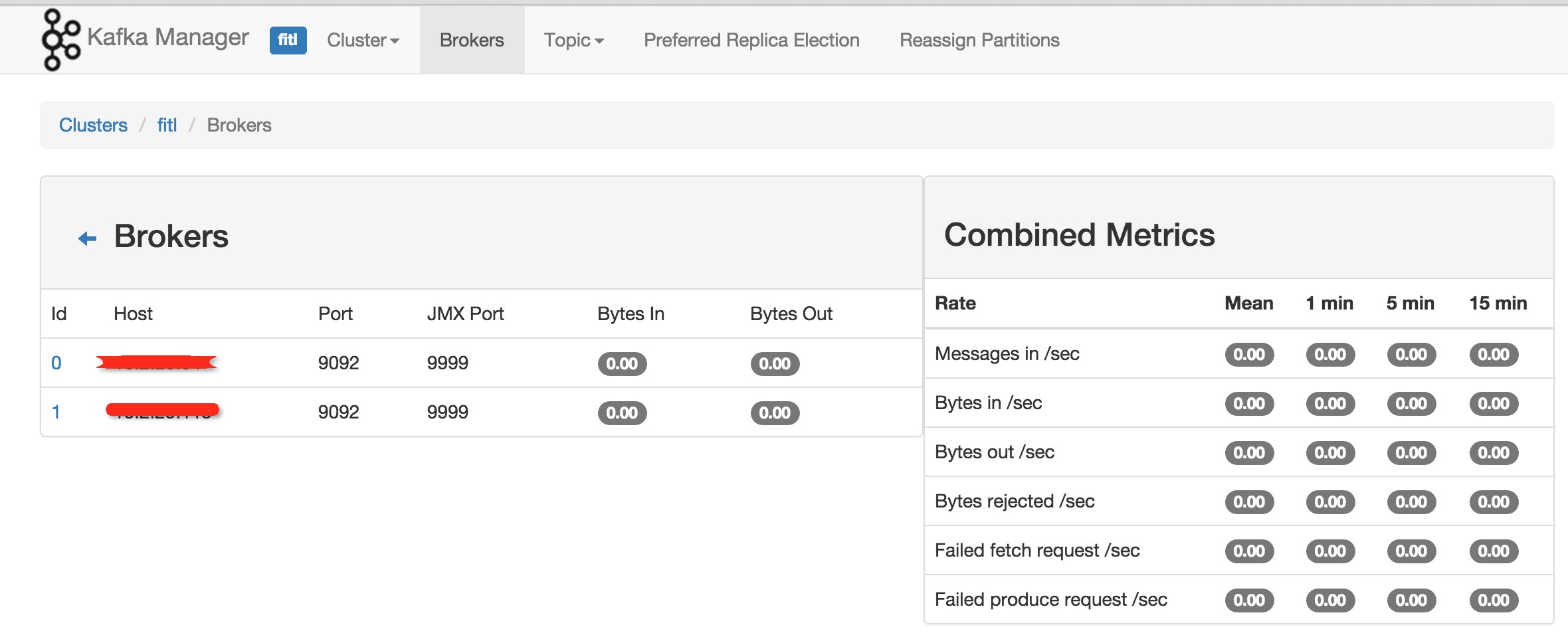
这样重启kafka后,通过kafka-manager的web界面可以监控到性能指标。