1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
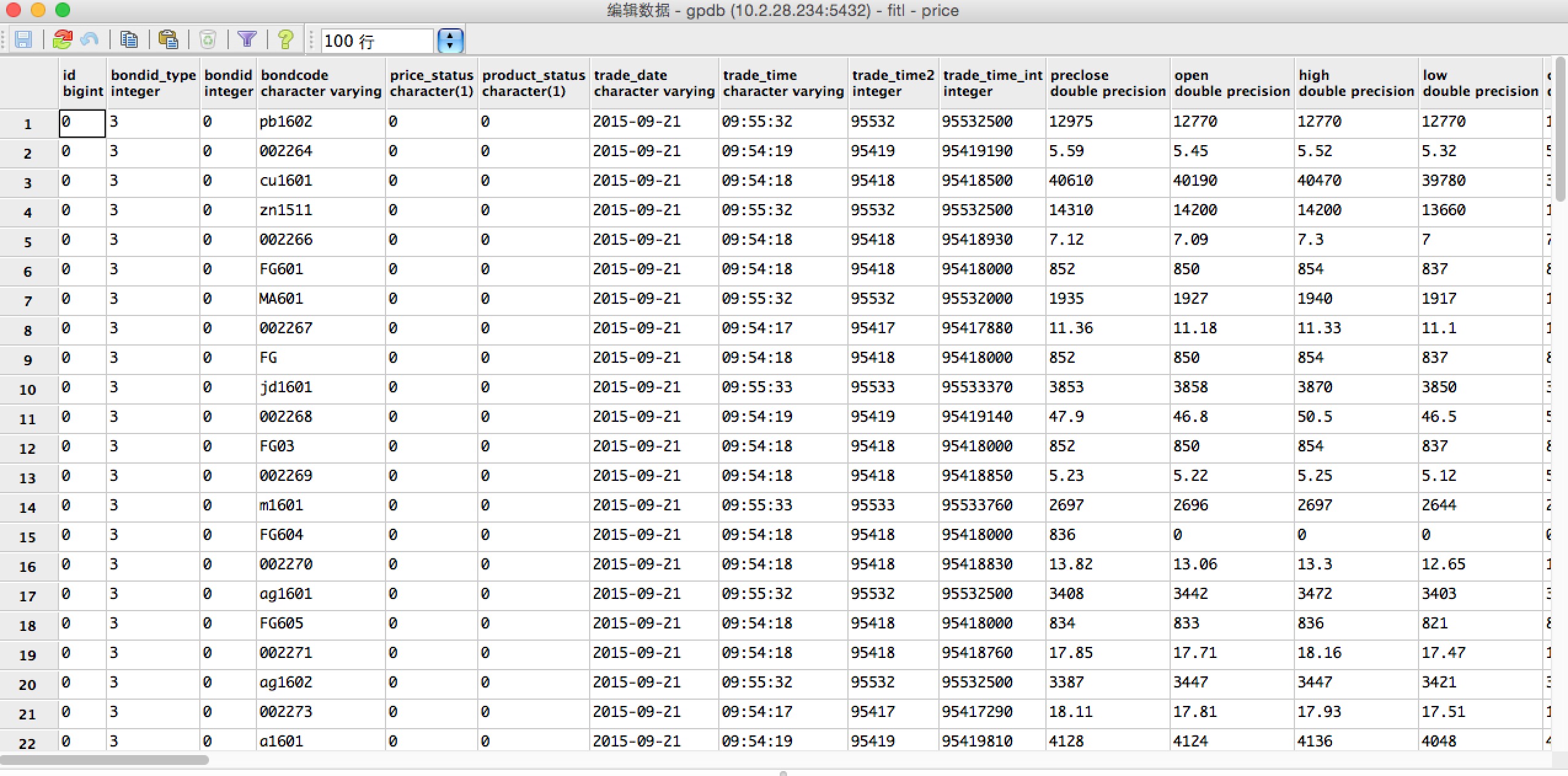
| create table price(
id bigint,
bondid_type integer,
bondid integer,
bondcode varchar,
price_status char,
product_status char,
trade_date varchar,
trade_time varchar,
trade_time2 integer,
trade_time_int integer,
preclose float,
open float,
high float,
low float,
current float,
volume integer,
turnover float,
trade_num float,
total_BidVol float,
total_AskVol float,
Weighted_Avg_BidPrice float,
Weighted_Avg_AskPrice float,
IOPV float,
Yield_To_Maturity float,
High_Limited float,
Low_Limited float,
pe1 float,
pe2 float,
delta float,
Ask_Price1 float,
ask_volume1 float,
ask_order1 integer,
Ask_Price2 float,
ask_volume2 float,
ask_order2 integer,
Ask_Price3 float,
ask_volume3 float,
ask_order3 integer,
Ask_Price4 float,
ask_volume4 float,
ask_order4 integer,
Ask_Price5 float,
ask_volume5 float,
ask_order5 integer,
Ask_Price6 float,
ask_volume6 float,
ask_order6 integer,
Ask_Price7 float,
ask_volume7 float,
ask_order7 integer,
Ask_Price8 float,
ask_volume8 float,
ask_order8 integer,
Ask_Price9 float,
ask_volume9 float,
ask_order9 integer,
Ask_Price10 float,
ask_volume10 float,
ask_order10 integer,
bid_Price1 float,
bid_volume1 float,
bid_order1 integer,
bid_Price2 float,
bid_volume2 float,
bid_order2 integer,
bid_Price3 float,
bid_volume3 float,
bid_order3 integer,
bid_Price4 float,
bid_volume4 float,
bid_order4 integer,
bid_Price5 float,
bid_volume5 float,
bid_order5 integer,
bid_Price6 float,
bid_volume6 float,
bid_order6 integer,
bid_Price7 float,
bid_volume7 float,
bid_order7 integer,
bid_Price8 float,
bid_volume8 float,
bid_order8 integer,
bid_Price9 float,
bid_volume9 float,
bid_order9 integer,
bid_Price10 float,
bid_volume10 float,
bid_order10 integer,
Pre_Open_interest integer,
Pre_Settle_Price integer,
open_interest integer,
Settle_Price integer,
Pre_Delta integer,
Curr_Delta integer,
Prefix varchar
)
WITH (appendonly=true,orientation=column,compresstype=QUICKLZ,COMPRESSLEVEL=1)
distributed by (trade_date) ;
|