Web应用的负载均衡、集群、高可用
问题
- 什么是无状态应用?
- 什么是负载均衡?
- 实现WEB负载均衡的方法有哪些?以及如何实现?
- 这些方案都有什么缺陷或问题?
- 会话保持、session复制、session共享
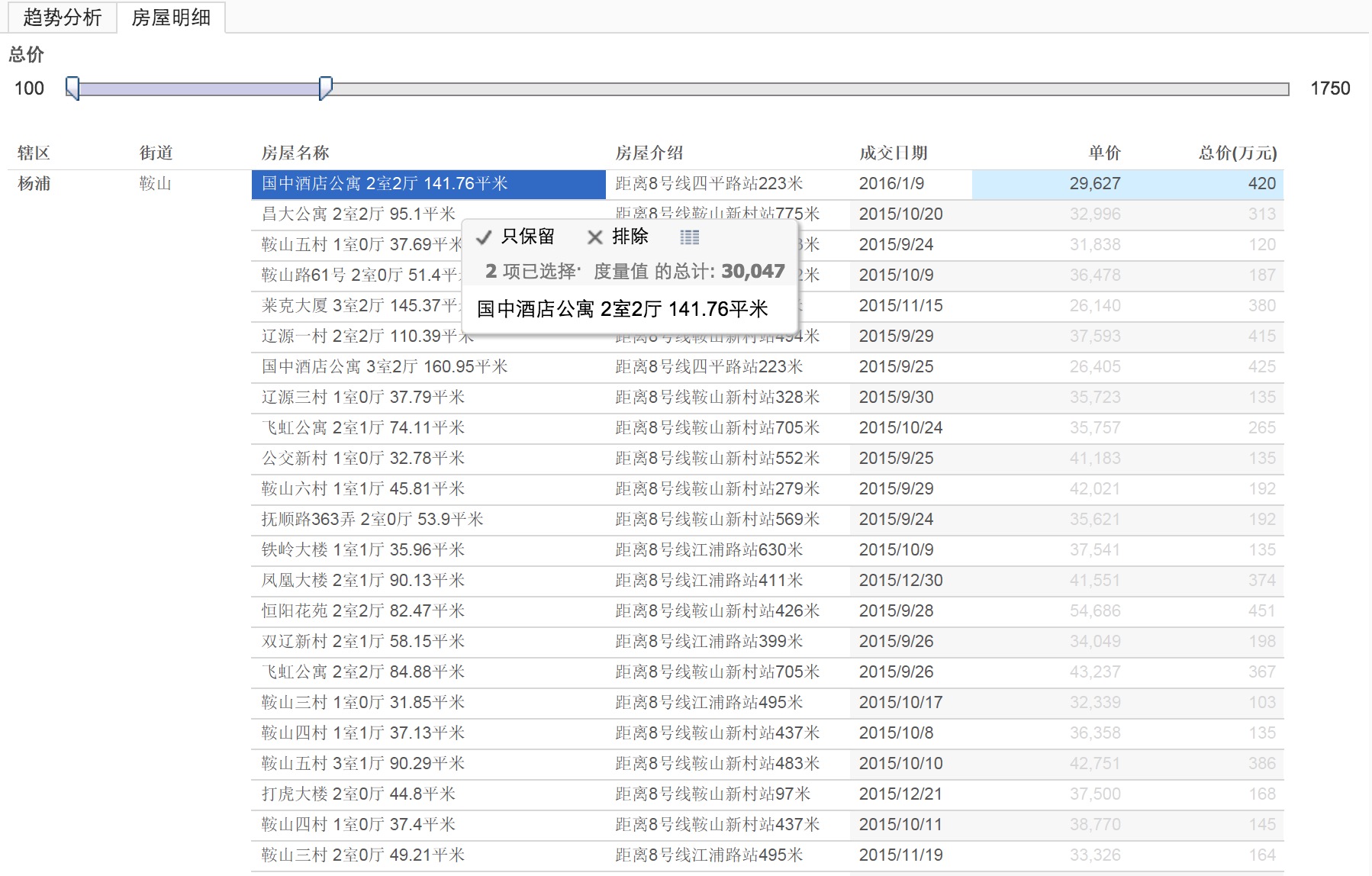
负载均衡
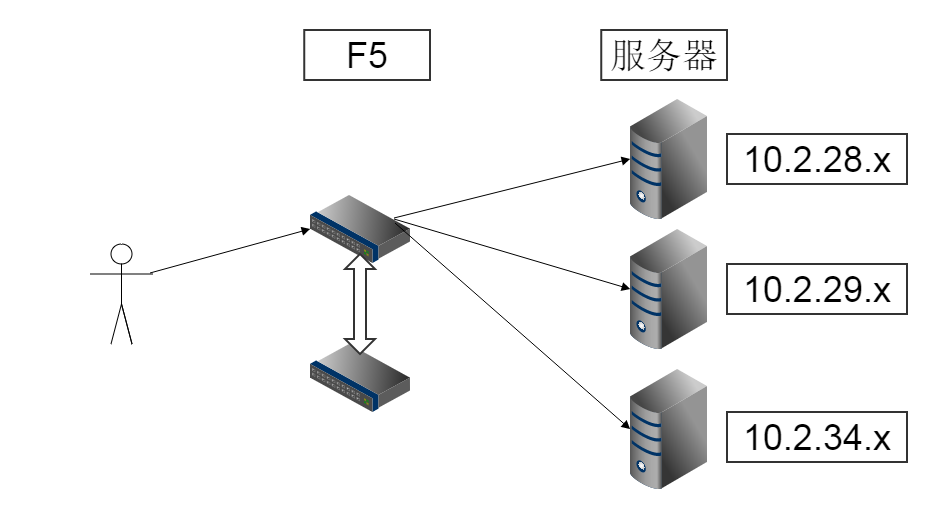
在实际应用中,在Web服务器集群之前总会有一台负载均衡服务器,负载均衡设备的任务就是作为Web服务器流量的入口,挑选最合适的一台Web服务器,将客户端的请求转发给它处理,实现客户端到真实服务端的透明转发。
最近几年很火的云计算以及分布式架构,本质上也是将后端服务器作为计算资源、存储资源,由某台管理服务器封装成一个服务对外提供,客户端不需要关心真正提供服务的是哪台机器,在它看来,就好像它面对的是一台拥有近乎无限能力的服务器,而本质上,真正提供服务的,是后端的集群。
集群
将相同服务部署在多台服务器上构成一个集群整体对外提供服务,这些集群可以是Web应用服务器集群,也可以是数据库服务器集群,还可以是分布式缓存服务器集群等等。
高可用
指以减少服务中断时间为目的的服务器集群技术。它通过保护用户的业务程序对外不间断提供的服务,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度。
session复制/共享
在访问系统的会话过程中,用户登录系统后,不管访问系统的任何资源地址都不需要重复登录,这里面servlet保存了该用户的会话(session)。如果两个tomcat(A、B)提供集群服务时候,用户在A-tomcat上登录,接下来的请求web服务器根据策略分发到B-tomcat,因为B-tomcat没有保存用户的会话(session)信息,不知道其登录,会跳转到登录界面。
这时候我们需要让B-tomcat也保存有A-tomcat的会话,我们可以使用tomcat的session复制实现或者通过其他手段让session共享。
几个组件
-
apache
它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代理服务器,支持安全Socket层(SSL)等等,目前互联网主要使用它做静态资源服务器,也可以做代理服务器转发请求(如:图片链等),结合tomcat等servlet容器处理jsp。
-
ngnix
俄罗斯人开发的一个高性能的 HTTP和反向代理服务器。由于Nginx 超越 Apache 的高性能和稳定性,使得国内使用 Nginx 作为 Web 服务器的网站也越来越多,其中包括新浪博客、新浪播客、网易新闻、腾讯网、搜狐博客等门户网站频道等,在3w以上的高并发环境下,ngnix处理能力相当于apache的10倍。
参考:apache和tomcat的性能分析和对比
-
lvs
Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟的服务器集群系统。由毕业于国防科技大学的章文嵩博士于1998年5月创立,可以实现LINUX平台下的简单负载均衡。了解更多,访问官网。
-
keepalive
这里说的keepalive不是apache或者tomcat等某个组件上的属性字段,它也是一个组件,可以实现web服务器的高可用(HA high availably)。它可以检测web服务器的工作状态,如果该服务器出现故障被检测到,将其剔除服务器群中,直至正常工作后,keepalive会自动检测到并加入到服务器群里面。实现主备服务器发生故障时ip瞬时无缝交接。它是LVS集群节点健康检测的一个用户空间守护进程,也是LVS的引导故障转移模块(director failover)。Keepalived守护进程可以检查LVS池的状态。如果LVS服务器池当中的某一个服务器宕机了。keepalived会通过一 个setsockopt呼叫通知内核将这个节点从LVS拓扑图中移除。
-
memcached
它是一个高性能分布式内存对象缓存系统。当初是Danga Interactive为了LiveJournal快速发展开发的系统,用于对业务查询数据缓存,减轻数据库的负载。其守护进程(daemon)是用C写的,但是客户端支持几乎所有语言,服务端和客户端通过简单的协议通信;在memcached里面缓存的数据必须序列化。
-
terracotta
是一款由美国Terracotta公司开发的著名开源Java集群平台。它在JVM与Java应用之间实现了一个专门处理集群功能的抽象层,允许用户在不改变系统代码的情况下实现java应用的集群。支持数据的持久化、session的复制以及高可用(HA)。详细参考
为什么需要回话保持
对于需要交互,或者事务型的网站应用,做了web负载均衡的集群后,需要解决session同步的问题。因为经过负载均衡调度器,同一IP的客户端连接可能会被分配到不同的真实服务器上(real server),如果session不同步的话,会影响交互或者事务的连续性。比如,用户登录的状态。
负载均衡的软件一般都提供持久连接的功能,即同一IP客户端的连接在设定的时间段内都分配到同一个real server。比如lvs的persistent,nginx的ip hash 和haproxy的source调度算法。这样处理实现最为简单,但一定程度上会影响调度分配的均衡性。
如何实现会话保持
通过组播的方式在集群间共享session,比如tomcat目前就具备这样的功能。优点是web容器自身支持,配置简单,适合中小型网站。缺点是当一台real server上的session变更后会将变更的数据以组播的形式分发给集群间的所有节点,对网络和所有的web容器都是存在开销。集群越大浪费越严重。不能做到线性的扩展。
将所有real server的session的存储路径指向同一台后端的共享存储(比如nfs服务器)。这样所有的web服务器向同一个位置获取session数据,在网络中session只有一份。相比前面组播的方式来说,网络开销较小。缺点是受制于存储设备的依赖,如果存储设备down掉,就无法工作了,要做存储的高可用,避免断点故障。另外,当访问量过大时,磁盘的IO也是一个非常大的问题。
把session信息存储在数据库中,通常使用内存表,以提高Session操作的读写效率
这个方案的实用性比较强,应用较为普遍。缺点在于Session的并发读写能力取决于数据库的性能,同时需要我们自己来实现Session淘汰逻辑,以便定时从数据表中更新、删除Session记录,当并发过高时容易出现表锁,对数据库造成较大压力
session是以文件的形式存放在服务器端的,而cookie是以文件的形式存放在客户端的。以cookie作为中转站,将用户的session 数据全部放在cookie中,服务器从cookie中读取session数据,做到同步。这样做的优点是减轻了服务器端的开销,简化了服务器架构,很多大型站点都在这么干。缺点有三:1.用户可能在浏览器中禁用cookie;2.cookie的数据大小有限制;3.cookie是可伪造的。
这可能也是目前互联网中比较流行的一种用法。所有Web服务器都把Session写入到memcache,也都从memcache来获取。 memcache本身就是一个分布式缓存,便于扩展。网络开销较小,几乎没有IO。性能也更好。缺点,受制于Memcache的容量(除非你有足够内存存储),如果用户量突然增多cache由于容量的限制会将一些数据挤出缓存,另外memcache故障或重启session会完全丢失掉。